Why A100?
NVIDIA A100
The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration to many domains - AI Training, AI Inference, HPC, and data analytics. The A100 is the current-generation engine of the NVIDIA data center platform and provides significant advantages over all classes of desktop GPUs, and prior-generation NVIDIA products.
Other than raw performance, users should be aware of several key technologies.
Tensor Float (TF32) data type
NVIDIA A100 introduces a new hardware data type called 'TF32' which speeds single-precision work, while maintaining accuracy and using no new code. TF32 is a hybrid data type that delivers sufficient precision for tensor operations without the full size of FP32 that slows processing and bloats memory.
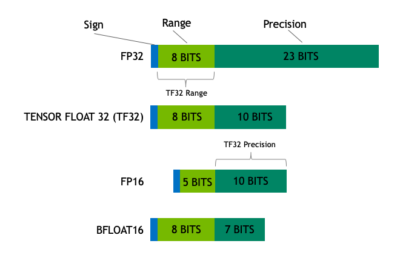
The result is an 8X speed improvement over FP32 where the reduced precision still matches FP16. This is optimal for matrix math used in Machine Learning.
Structural sparsity
Sparsity is an optimization technique that creates a more efficient network from a dense network, and can make better predictions in a limited time budget, react more quickly to unexpected input, or fit into constrained deployment environments.
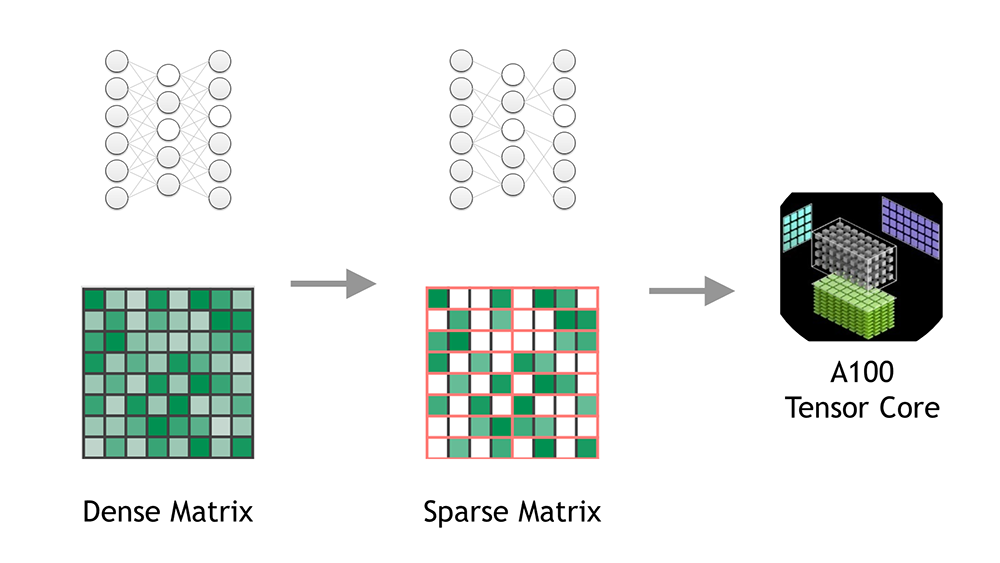
Use of sparsity for inferencing achieves 2X performance improvement for TF32, FP16, and INT8 operations over non-sparse operations.
Double-precision floating (FP64)
IEEE 754 double-precision binary floating-point format provides 16 decimal digits of precision. This is format is used for scientific computations with strong precision requirements.
Most GPUs have severely limited FP64 performance - operating at 1/32 of FP32 performance. The A100 computes FP64 at 1/2 of FP32 which is a dramatic acceleration over CPU, desktop GPUs, and other data center GPUs.
NvLink for advanced multi-GPU
Denvr Cloud HGX systems include NVIDIA Gen4 NvLink (SXM4) which provides 600 GB/s of GPU-to-GPU bandwidth. This is an over 8X improvement over PCIe Gen4 which offers 64 GB/s of bandwidth. This architecture is critical for models that require more GPU working memory than in available in a single GPU (up to 80 GB).

Denvr Cloud's 800G InfiniBand networking uses HGX systems to create logical multi-node clusters. Multi-node is required for Large Language Models (LLM) training like GPT-3 that are unachievable with Ethernet-based multi-node clusters.
Multi-Instance GPU (MIG)
MIG partitions the A100 GPU into as many as seven instances, each fully isolated with its own high-bandwidth memory, cache, and compute cores.
This allows Denvr to offer 'fractional' A100 GPUs to clients with 10GB or 20GB memory configurations. The benefits of this are:
- Allocate only GPU resources needed for a job
- Cheaper than a full NVIDIA A100 GPU
- Access the TF32 data type and sparse operations for learning and analytics, before training full data sets on full GPU or multi-GPU configurations.
GPU specifications
The following chart shows absolute performance characteristics for the NVIDIA A100 GPU. The relative speeds should be considered along with data type scale/precision to achieve the best performance.
Operations per second | With Sparsity | |
FP64 | 9.7 TFLOPS | - |
FP32 | 19.5 TFLOPS | - |
TF32 (Tensor Float) | 156 TFLOPS | 312 TFLOPS |
BFLOAT16 | 312 TFLOPS | 624 TFLOPS |
FP16 | 312 TFLOPS | 624 TFLOPS |
INT8 | 624 TOPS | 1,248 TOPS |
Related Articles
Monitoring GPU performance
Introduction This document will demonstrate several techniques that can be used to observe GPU utilization. GPU monitoring is critical in understanding how effective your application is at utilizing attached GPUs. We will use Ubuntu 20.04 Application ...Storage platform overview
The Denvr Cloud is integrated with a high-performance storage platform that maximizes overall system performance. There are three separate storage systems that work together to deliver throughput, parallel I/O, and high IOPS, as well as ...Connect to GitHub using SSH keys
As of August 2021, GitHub has removed support for Password Authentication while using HTTPS protocol. It is convenient (and recommended) to access GitHub repos securely using SSH Keys. Generate a public/private RSA key pair Skip to next step if you ...Using two-factor authentication (2FA)
Denvr Cloud supports two-factor authentication (2FA) using Google Authenticator. 2FA is highly recommended for account security and is managed by the Tenant Administrator. Tenant authorization for 2FA The Tenant Administrator controls if users are ...Terms of Service
For details on our data policy, please see our Terms of Service and Privacy Policy. You will also have a Master Services Agreement as part of client onboarding.